Could you imagine that a computer program can infer the nutritional content of some food item from reading articles on related topics? How about an algorithm that can give medical diagnoses based on radiological images? Although these abilities sound like science fiction, they are becoming closer to reality thanks to the recent integration of computer science and cognitive science. In cognitive science, plenty of cognitive models have been established and developed over decades to explain and describe human cognitive processes in a computational language. However, despite their exceptional explanatory power, cognitive-process models suffer from a major limitation: almost all cognitive experiments are done in a lab setting where participants are asked to interact with visually simplified stimuli on a computer screen. For example, they could be asked to categorize a bunch of shaded squares varying in size and darkness. However, limiting cognitive research to only artificial stimuli raises the question of whether the same findings about human cognition still hold true for real-life situations. Thanks to the advancement of computer science, there is now a potential solution to this problem.
As a popular computer-science tool, the neural network is a computer program that takes in snippets of text or images of natural objects in their raw digital forms (e.g., pixel values of an image) and spits out a meaningful prediction about the identity of the input item (e.g., labeling an image as depicting a cat versus dog). The input data is passed through a multi-staged network consisting of interconnected “neurons,” each of which perform complex computations that eventually lead to the prediction of the object category. Interestingly, besides the exceptional ability of the models to make such predictions, cognitive scientists recently found that the numbers in the intermediate layers also encode valuable information about human cognition, which can be used for predicting the results of human decision-making in natural contexts.
To give a specific example, say we have a neural network trained to predict the common types of felines. We start off by feeding the neural network three pictures, a house cat, a caracal, and a tiger. Then instead of focusing on the category predictions made by the network, we read off a list of numbers produced on a near-end stage of computation. Importantly, the numbers extracted from the network encode information about the perceived similarities between different felines. To gain some visual intuition, researchers treat the numbers associated with each feline as coordinate values of a point in a multidimensional space, such that each feline can be represented as a point. In such a space, the notion of similarity between two felines can be physicalized as the distances between the corresponding points. As it turns out, the felines that are perceived by humans as more physiologically similar, in this case, the cat and caracal, turn out to also be closer in space as compared with the distance between the cat and tiger.
Moreover, once we map out the representations of more feline animals covering a variety of categories, we start to see a clustered organization of animals resembling human-like conceptual grouping of various feline animals. For instance, leopards and cheetahs lie in a cluster quite distant from that of a house cat and a caracal, while within the cat-caracal cluster, various breeds of house cats are in a distinct sub-cluster from the caracal. Inspired by the representational power of the deep neural network, cognitive scientists have begun combining network-derived representations with cognitive-process models to study human cognition in natural contexts. I will describe two very different examples to showcase the general application of such modeling applications.
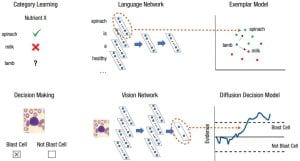
In the first experiment, participants were told whether a hypothetical nutrient is present in various foods and then asked whether other food items also contain that nutrient. In other words, participants learned a few examples of food items that either contain a certain nutrient or not and were instructed to determine if an unlearned food item also has that nutrient. Intuitively, people tend to believe that foods that share many otherwise similar properties will also have similar nutrient compositions. For example, by knowing that lemon is rich in vitamin C, most people would infer that lime, a biological cousin to lemon, is also rich in vitamin C. Following this intuition, researchers modeled the categorization process using the exemplar model of categorization. This process predicts whether a novel food item has a certain nutrient by comparing how closely related the food item is to the learned examples of food items that contain that nutrient and those that don’t.
The neural networks play a crucial role in quantifying the similarity relations between different food items. The similarities are measured in a similar way as in the feline example. In this example, online articles on the health-related topics of lemons and limes are first input into the neural networks, from which the activation values of some “neurons” are taken as the numeric representation for both fruits. Based on the numeric representations, the lemon and lime are represented as two points in a multidimensional space. The physical proximities between them become an intuitive measure of how closely they are related. Interestingly, the networks are trained to infer the nutrient composition of the food items based on the text-based patterns alone. For example, since there are many articles advertising that lemons are good for our heart, which is due to their high vitamin C content, the neural network will learn to be sensitive to the co-occurrence of the words “heart” and “good” as an indication of the presence of vitamin C. As such, the network can encode information about the nutrient profiles of different food items based solely on text-based patterns.
In the second experiment, participants were asked to judge whether cells shown in various medical images were blast cancerous cells. Intuitively, decision-making can be viewed as a back-and-forth thinking process where someone vacillates on the decision to call a cell cancerous from moment to moment as they notice subtle signs indicative of either healthy or cancerous cells. Such a deliberation process is precisely described by the drift diffusion model. Essentially, the model captures several intuitive ideas about decision making based on evidence in quantitative terms. First, the decision maker starts with a neutral stance as he/she has zero evidence as to whether the cell is cancerous. Depending on whether a sign indicative of a cancerous/healthy cell is noticed at any given moment, a certain amount of evidence is added/subtracted towards claiming the cell to be cancerous. Second, the evidence, whether positive or negative, is accumulated over many time steps. So, noticing multiple signs of a cancerous cell in a row will result in strong positive evidence for the cell being cancerous, whereas observing alternate signs of cancerous and healthy cells will translate to little evidence in either direction. Third, once the amount of the evidence (either positive or negative) reaches a certain threshold, the model will predict a final decision as to whether the cell is cancerous. Notably, the magnitude of the decision threshold represents how deliberate or impulsive of a decision maker someone is. For example, a more deliberate decision maker is characterized by a higher decision threshold, so that more evidence needs to be observed indicative of a cancerous cell before he is confident enough to claim that the cell is cancerous.
Importantly, the neural networks play a critical role in determining the level of evidence attributed to different cell images. Having been trained on thousands of cell images from healthy and patient cases, the neural network used in the experiment can compute the objective probabilities of the cell being cancerous. If a cell image is fed into the network which shows all signs indicative of cancer, then the network will predict a very high probability of a cancerous cell, which translates to strong positive evidence. On the other hand, if the input cell image has mixed signs of a cancerous and a healthy cell, then the network will predict nearly equal probabilities of both cases thus weak evidence.
To fully explain human decision-making processes, another model component needs to be added to account for the fact that thinking proceeds in a back-and-forth fashion. Bear in mind that the probabilities given by the neural networks are based on a thorough pixel-by-pixel analysis of the cell images, but humans, even medical experts, tend to focus on only one diagnostic feature at a time, not to mention that some features are too subtle to be perceived at all. To bridge this discrepancy, a random noise is added to the amount of evidence at each time step such that a generally cancerous cell may occasionally be counted as healthy upon seeing a healthy sign and vice versa. Notably, the model predicts that the weaker the underlying evidence based on the objective probabilities is, the larger the impact of noise. This is consistent with our general intuition; for an ambiguous object that is difficult to categorize, people tend to spend a lot of time pondering over the decision and often change our minds as we think more about it, all of which are predicted by the cognitive model.
By coupling the explanatory power of cognitive models with the numeric representations yielded by neural networks, these computer programs can accomplish cognitive tasks more efficiently and accurately than most well-trained human experts. With computational models quantifying human cognitive processes, computer scientists can create more tools for completing tasks that traditionally demand laborious work of human experts, such as identifying animal species and diagnosing medical conditions. With machine-learning techniques extracting statistical regularity from real-world data, cognitive scientists can study more complex aspects of human cognitive processes that is only observable in natural context, such as how we make inferences about the nutritional composition of a novel food item based on our collective knowledge of how different foods relates in terms of nutrition.
Despite the power of the synergy, we still need to be mindful of the simplistic assumptions scientists make when choosing the training data for the neural networks and when formulating the equations for the cognitive processes. For example, if a neural network is trained to classify felines by learning the correct labels provided by a cat expert, then the network will not be well suited for predicting how a novice would make the classification. If the same equations are used to describe individual thinking processes, then the cognitive models will not be able to predict the personal differences in thinking. Nevertheless, I believe that with further development in both cognitive and computer sciences, more diverse training data will be collected, and more elaborate cognitive models will be devised that can account for the intriguing complexity of human cognition.
References:
Bhatia, S., & Aka, A. (2022). Cognitive modeling with representations from large-scale digital data. Current Directions in Psychological Science, 31(3), 207-214.
Holmes, W. R., O’Daniels, P., & Trueblood, J. S. (2020). A joint deep neural network and evidence accumulation modeling approach to human decision-making with naturalistic images. Computational Brain & Behavior, 3(1), 1–12.
Jha, A., Peterson, J., & Griffiths, T. L. (2020). Extracting low-dimensional psychological representations from convolutional neural networks.
Zou, W., & Bhatia, S. (2021). Learning new categories for natural objects. In Proceedings of the 43rd Annual Meeting of the Cognitive Science Society (pp. 2575–2581).
Edited by Joe Vuletich and Gabriel Nah

Leave a Reply