
This post is from ScIU’s archives. It was originally published by Lana Ruck in February 2018 and has been lightly edited to reflect current events.
Tomorrow will be the 134th official Groundhog Day in the United States. Celebrated in Canada, Germany, and the U.S., the holiday derives from a long-standing German-Dutch tradition, which we’ve been officially recording since 1886. The basic idea: if a groundhog emerges from his hole and sees his shadow, winter will last for six more weeks, but if he sees no shadow, an early spring is on the way.
Why are we discussing this arguably adorable tradition on a science blog, you ask? Although there’s much we can learn about the tradition (and lots of lore!), Groundhog Day is our post topic this week because it’s a great way to explore the basic concepts of probability. Scientists use probability theory every day in their research, most notably, to make sure that the phenomena we are studying are not due to random chance. Probabilities can be complex, but even in their simplest form — as is the case with Groundhog Day — the questions we can answer using probability theory are often quite interesting.
Meet Punxsutawney Phil (below), the official groundhog whose shadow we will all be celebrating, or not celebrating, this Friday. Our basic question, of course, is: how much can we trust Phil’s weather predictions?

To answer this with probability theory, we need to know Phil’s prediction history for each year since 1886, and the actual weather patterns recorded for those years. Although there are a few missing data points, over the years, Phil has predicted 103 “long winters” and 19 “early springs.” Metrics on the actual weather patterns are more complicated1. Lucky for us, we can use data from the Farmer’s Almanac.
According to the Almanac data, Phil has been correct 39% of the time. That alone suggests that we should be a bit skeptical of poor Phil. However, a more reliable approach that scientists often use to evaluate their own data comes from applying probability theory to these data. Is Phil really that bad at predicting weather when we compare him, for example, to a coin toss? He was right 39% of the time, after all!
To answer this, we use a binomial distribution to compare the number of correct guesses — 48 correct out of 122 total guesses — to the number of correct guesses we’d get by chance — 50%, or 60 out of 120. Based on this principle2, Phil’s predictions really are worse than a coin toss. In fact, it seems like your best bet is actually to expect the opposite of Phil’s prediction!
We already know that Phil has gotten far fewer than the expected 60 correct guesses, but splitting the data into more categories can help us detect not just if, but where he differs from random chance. To do this, we can put information about Phil’s predictions and the actual weather patterns together to create a new variable, which still shows how Phil was either correct or he was incorrect, but breaks each of these into every possible way that they can happen:
Two cases in which Phil is correct are:
1. Phil predicts winter, winter persists
2. Phil predicts spring, spring begins
Two cases in which Phil is incorrect are:
3. Phil predicts winter, spring begins
4. Phil predicts spring, winter persists
As we did before, we can use probability theory to evaluate these data using coins, by flipping two at a time. We would do this 120 times and see how many times we get each of the following possibilities, which mimic Phil’s predictions and the resulting weather patterns:
Two cases in which the coin tosses are the same:
1. Heads, Heads
2. Tails, Tails
Two cases in which the coin tosses are different:
3. Heads, Tails
4. Tails, Heads
Because this is a simple coin toss, we should expect that the same number of coin tosses will fall into each of the above categories, so each should occur about 30 times. We then compare our coin toss results — which represent “random chance” for each category — to each of Phil’s four categories3 (see graphic below). This forms the core of the chi-squared statistic, which we can use to evaluate Phil’s job as a weatherman in detail.
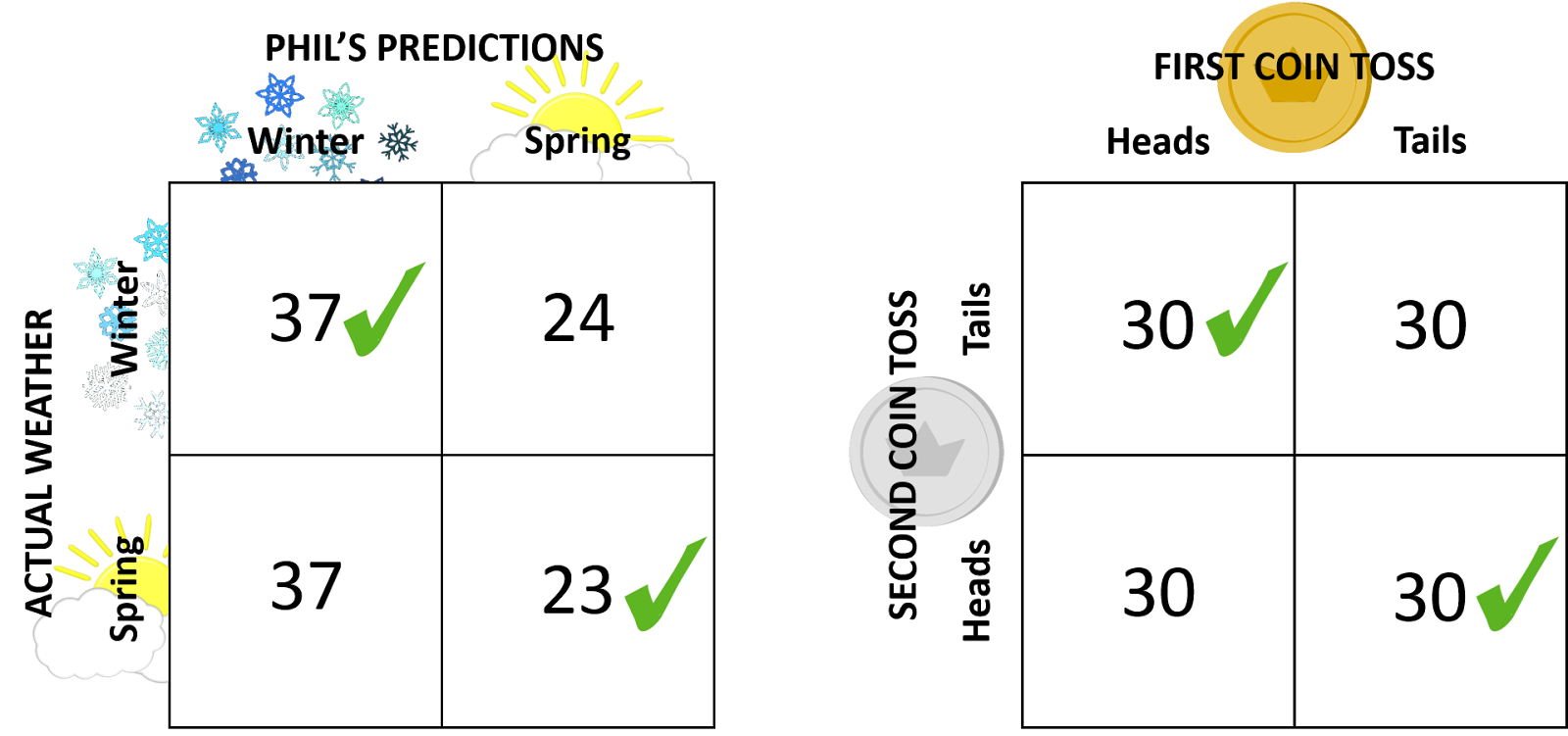
We could, for example, find out if Phil is better at predicting spring than winter, by seeing if his winter-winter and spring-spring guesses are similar to each other, or very different (we have conservatively split his guesses in half, 24 and 23, respectively, but his actual numbers could be more like 46 and 2, respectively, and these would be very different from the random chance data). We can also find out if Phil has gotten worse over time, how he compares to other “imposter” groundhogs, or even if he is more accurate than the Farmer’s Almanac itself (via NPR)! We do this all by comparing the observed frequency data — which will differ for Phil, other groundhogs, the Almanac, etc. — against our totally random (or null) coin-flip distributions.

Phil enthusiasts aside, we likely agree that Phil isn’t a trusty weatherman, and as several NPR poll respondents noted (see poll data, to the right): he’s certainly less reliable than just stepping outside! Still, I’m glad he’s out there as an example of real-life probability.
Edited by Rachel Skipper and Kimberly McCoy
______________________________________________________________________
1 For example, the actual weather each year can also be considered a binary variable, with the two options being: winter lasted for 6 more weeks, or spring came early. But where should we take our measurements from — Phil’s home of Punxsutawney, PA? The contiguous 48 states? All 50? The globe?! Once we define the region for our data, how do we collapse its daily weather patterns from February 2nd to Mid-March into only two categories (consider that just last week, Bloomington had temperatures in the low-20’s, the high-50’s, and snow and rain, all in a 3 day span…)? Issues like these perfectly illustrate how careful scientists must be when considering how to collect their data and design research.
2 ”Under the hood” the binomial distribution is actually more like flipping the coin a million times, and then taking, say, 5,000 random samples of 120 coin flips from this huge set of flips, and counting how many times the sample is split at least as unevenly as Phil’s — 47 correct guesses to 74 incorrect ones. The probability of getting a sample with only 47 correct out of 120 is tiny: about 20 in 5,000 samples, or 0.4%. This incredibly low probability means that Phil’s performance is very unlikely to occur by random chance, and exemplifies a concept commonly represented in science papers as a p-value. P-values are used widely in science because they help us decide whether our results are more likely to be true effects or, in contrast, might be due to random chance. Using this approach, we can evaluate any test statistic against a random chance threshold, like 5% (or p < 0.05), to determine if our results are significant; Phil’s p-value of 0.004 is much smaller than this threshold, and so, unfortunately, his numbers are likely not due to random chance — Phil really is bad at predicting the weather.
3 The available Almanac data, unfortunately, is not split in this way. So, as a conservative example, we have simply divided Phil’s correct guesses and incorrect guesses in half. Although his actual data might be very different from our example, they still help to illustrate what chi-squared contigency tables look like.

Leave a Reply