by Rebecca Holte Manager, Audio and Moving Image Preservation, Digital Collections Services, New York Public Library
Special thanks to Mike Casey for inviting me to participate in this series, and to my NYPL colleagues: Genevieve Havemeyer-King, Media Preservation Coordinator (primary vendor liaison and specification and quality control manager), Ben Turkus, Assistant Manager – Audio and Moving Image Preservation (lab manager), and Nick Krabbenhoeft, Manager – Digital Preservation.
Introduction
The New York Public Library (NYPL), like IU Bloomington, Harvard University, and so much of our cultural heritage community, has recognized the risks inherent in its recorded audio and moving image collections. While our mass-digitization efforts really scaled up a couple of years after IU’s, we’ve made significant progress and are thrilled to finally be at a point where we’re able to share some cumulative data with the community.
To provide a little background, NYPL’s audio and video labs were born within performing arts curatorial divisions and were built up to fulfill both the preservation and access needs of those units. The labs were united under the Preservation Division roughly 10-15 years ago to serve all NYPL Research Centers (prioritizing special collections). Around the same time, digitization-to-file became a routine practice for audio, with video following a few years later.
In 2014, NYPL completed an audio and moving image (AMI) collection assessment funded by the Mellon Foundation, where we found that we held over 800,000 AMI recordings in the Research Centers, nearly 230,000 of which were a preservation priority. And as we’ve progressed with an item-level inventory and incorporated new acquisitions, that number has easily exceeded a quarter-million recordings. Our endeavor to ramp up our preservation efforts has been titled the NYPL Audio and Moving Image Initiative. By the end of 2019, we will have digitized more than 180,000 recordings, and mass digitization efforts work will continue for at least the next few years. The initial phase has focused on magnetic and optical media, with film digitization to begin in 2020 and grooved media (discs, cylinders) at a future date.
NYPL Collections
NYPL’s audio and moving image collections run the gamut from personal/private or experimental recordings, unreleased interviews and performances, performing arts rehearsals and productions, to radio or television broadcasts. To give just a few collection examples, some recent acquisitions that we’re really excited about include collections with material by Lou Reed, Sonny Rollins, and Fab 5 Freddy. NYPL also has a history of sponsoring original documentation, which includes the Louis Armstrong Jazz Oral History Project, dance original documentation and oral history projects, and recordings of Broadway, Off-Broadway, and regional theatre productions. A list of research divisions can be found at https://www.nypl.org/research-divisions/; filter by media to find divisions collecting “sound recordings” or “film & video”.
Collection materials can be accessed through three primary avenues: the Archives Portal, the Catalog, and Digital Collections. Archival and catalog records lead to Digital Collections, where you can stream recordings available globally or onsite at NYPL, depending on rights profiles. More and more recordings are added as we complete post-digitization processes, a multi-step effort that encompasses quality control, ingest to repository and streaming environments, archival/catalog processing, metadata conformance, and application of rights and permissions.
The data
The data described in this blog post is derived from a sample of 96,137 physical media items—73,208 audio and 22,929 video—across magnetic and optical formats. The data has been culled from sidecar JSON metadata files, though we also use MediaInfo directly on the files to cull/cross-check data in many scenarios.
What we’ve aggregated represents one information record per physical object. We recognize that, in many cases, there could be multiple preservation master files per physical object; this is especially true of audio formats like compact cassettes or open reel audio. In our case, it’s also useful to recognize that a single item-level identifier may represent multiple physical objects, such as two compact cassettes stored within a single case or, in more confusing scenarios, audio and video media stored within the same case. At any rate, data sharing often comes with qualifiers.
Audio preservation masters presented here are WAV at 24 bits/96,000 Hz, but NYPL has since moved to lossless compression with FLAC. File format and codec for video preservation masters vary due to extraction method or specification. In 2017, NYPL began using lossless compression for video using FFV1/Matroska—both MOV and MKV are demonstrated in this data set. Current NYPL specifications can be found at https://github.com/NYPL/ami-specifications.
The variety of summaries or visualizations presented below highlights the difficulty in making generalizations, or even in using the typical format recording capacity for estimation purposes. (This may also be due to the types of collections we acquire, which demonstrate a variety of uses, few of which are standardized or broadcast.) Different analyses are more suitable in different situations, such as estimating vendor services, long-term digital storage, streaming services, usable hours of content, etc.
If we take averages at a high enough level—such as all audio objects versus all video objects—we’ve found that all-things-being-equal average durations are around the one hour mark. However, the minimums and maximums show a concerning range from zero minutes to over 30 hours! In terms of file sizes, the all-things-being-equal comparison is notably skewed for video, as we transitioned from uncompressed to lossless (FFV1) compression during the period in which this data was gathered.
We do still find high-level generalizations useful for broad planning purposes. Additionally, even at this bird’s eye view, the extreme ends of the spectrum have clued us into quality control issues that may have otherwise been missed. Why were some files listed as having no duration? Do we truly have recordings that are nearly 2,000 minutes long? (More than 30 hours?! What does that mean for the patron experience? Or for the cataloger?) We have since put checks in place to review outliers. For example, updates to our JSON metadata schema and MediaConch policies now help identify files with durations that are shorter than 10 seconds or longer than 10 hours (the shortest and longest expected durations, respectively).

“Simple” statistics (all formats in sample, duration and file size)
When we initially began looking at the specific formats, we kept it fairly simple and calculated straight averages and minimums/maximums. This representation begins to demonstrate the variances that we encounter across the formats, but it certainly serves as a better tool for estimating purposes.


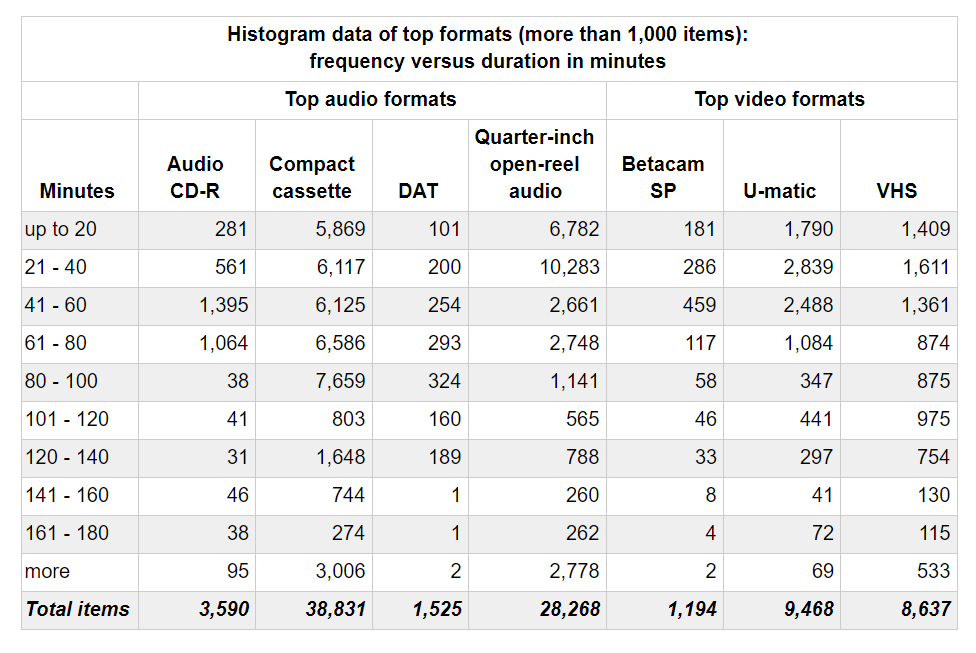
Histograms for data distribution (select formats, duration)
A histogram is an even more precise way of reviewing data, in which you can see spikes where the most common durations occur as well as the outliers that may skew any averages or assumptions. In our experience, it’s definitely not a smooth bell curve distribution. We haven’t made any correlation between durations and specific collections, but it would certainly be interesting if we could make some additional predictions based on the nature of collection or creator (for example, interview versus rehearsal versus broadcast content, etc).
The below charts demonstrate duration distribution for formats where we have more than 1,000 items in our set: audio CD-R, compact cassette, DAT,quarter-inch open reel audio, Betacam SP, U-matic, and VHS. You can use your favorite program to automatically establish the frequency ranges, but to make these below charts easier to read, we’ve used 20 minute increments. Selecting your own frequency ranges also means that you can build your analysis to suit – for example, to reflect known manufacturing standards, or to reflect vendor pricing tiers, or to demonstrate how many media might take longer than one typical working day to transfer!


Conclusion, next steps, etc…
These summaries and visualizations represent only one use of our compiled data. At some point, we will look more closely at capture issues, or reasons digitization was not possible. It will be especially useful to look at any trends based on manufacturer stock (we have had an extremely bad run of Agfa tape) both to test validity of any previous assumptions and to pre-emptively flag media that may require additional labor. (Do we wish to send those to our in-house labs, or do we want someone else to spend the time on it? Do we think the collection items are important enough to warrant the additional resources?) We’re also debating what level of granularity is truly useful: do we include number of channels? Mono versus stereo? Side one / side two? Speed changes or extended play? In which cases would we also need to cross-reference the creator, type of collection, or stock in order to predict anything?
Stay tuned! This is really our first pass at data consolidation and sharing, and we hope to do more as our work progresses.
[…] From a Post Guest on the Indiana University Media Digitization & Preservation Initiative Blog by Rebecca Holte Manager, A… […]