By: Michael Black
View fixtures and live scores from any league, on any day, straight from the terminal.
If you’re like me, you love football. And I’m not talking about the version where feet aren’t used and the ball isn’t a ball; I’m talking about football — the world’s most beloved game, and, if nothing else, the more aptly named of the two sports.
If you love football as I do, we have likely felt a similar frustration that comes with being a fan of the beautiful game: It is time-consuming and challenging to keep up with the schedules and results of five major domestic leagues + the UEFA Champions League when you’re a regular person with responsibilities and a poor memory.
Recently, after googling “La Liga fixtures” followed by “Premier League fixtures” followed by “Serie A fixtures” etc., for the thousandth time, I realized something needed to change.
What I wanted was a way to view the matchups of only the leagues I care about, on any given day, with minimal effort, straight from my terminal.
I decided to harness the powers of Python and Beautiful Soup and give it my best shot.
I will only be showing the web-scraping code for this article. I will add a link to my GitHub repository at the bottom of the article so that you can view the rest of the program in full and download it for your own personal use.
Step 1: Finding a Website
The first step to scraping information from the web is finding a site that has the information you are looking for (duh). This isn’t always as easy as it may seem, and there are some key differences in the types of sites you’ll encounter and how easily they can be scraped.
- Static Websites are displayed in a web browser exactly as they are stored. The web pages contain fixed content coded in HTML and stay the same for every viewer of the site.
- Dynamic Websites, on the other hand, contain information that changes, depending on factors such as the viewer of the site, the time of day, time zone, and the native language of the country of the viewer. Dynamic websites are interactive.
The short of it is that static websites are a bit simpler to scrape. As the title of the article states, I used Beautiful Soup to do my scraping; BS works great for static webpages, but not so much for dynamic.
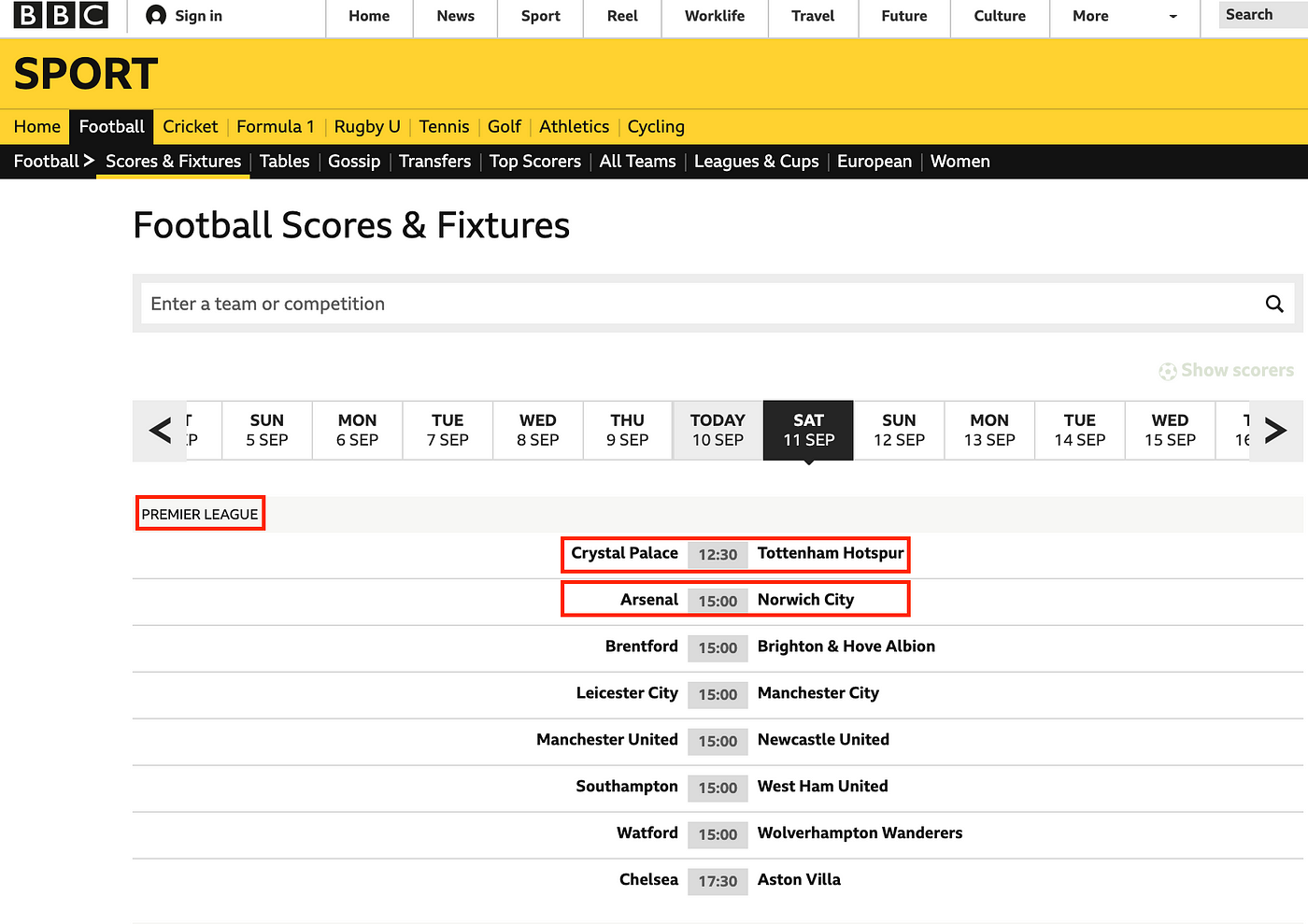
After a bit of searching and comparing, the site I settled on was bbc.com/sport/football/scores-fixtures:

The page is simple yet thorough and contains all of the information needed for my project. The page changes only slightly for live and finished games, as shown below:
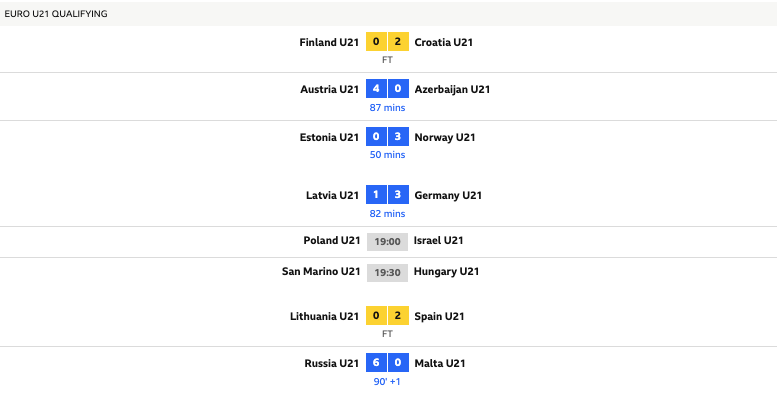
I am unable to click on team names or matchups to gather more information, which tells me the page isn’t interactive. Also, although I am accessing the page from the US, the game times are still being shown in British Summer Time (UK timezone). These are both indicators that the webpage is static, as discussed above.
Now that I’ve got a site, it’s time to scrape.
Step 2: Import Packages and Connect to the Website
I can call html_content:

This returns all of the HTML content from the webpage as a long string. Below, I run the variable through BeautifulSoup:
Which produces the following:
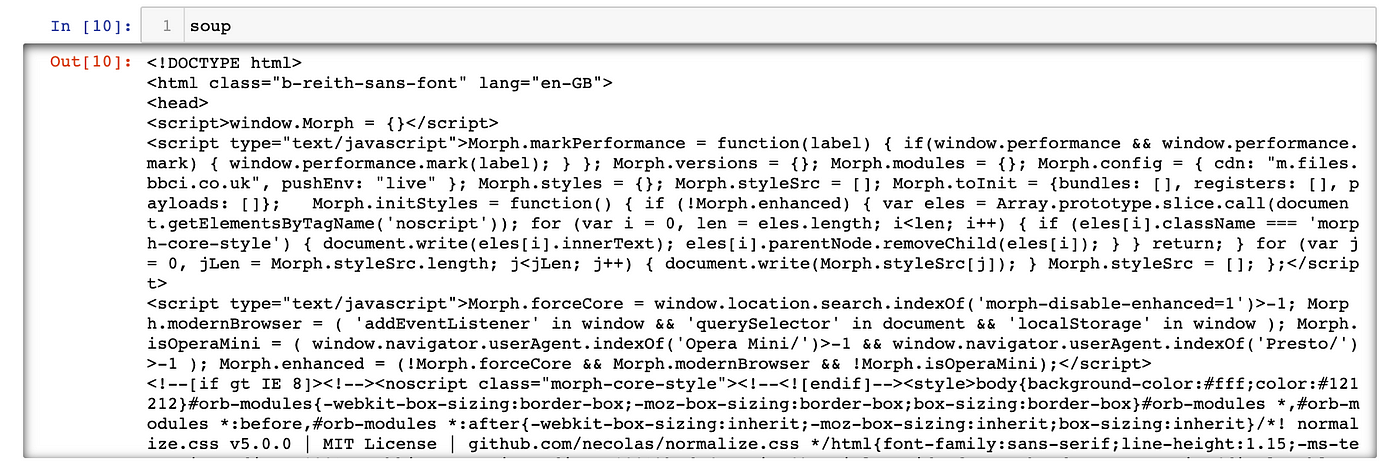
This has transformed html_content into a BeautifulSoup object, soup, which represents the content as a nested data structure. I can now easily search the object for HTML tags and specific data, which is shown in Step 4.
Step 3: Inspect the Page
Page inspection is essentially just locating the HTML identifiers for the information you need. Thinking about my project, I need identifiers for the following:
- League names
- Home and Away team names
- Game times
- Home and Away scores
- Minute-of-game (for live games) and ‘FT’ (Full Time) for completed games
To inspect any of those, you simply highlight them on the page, right-click, then select “Inspect”. Doing this to “Premier League” (league name) will give the following:
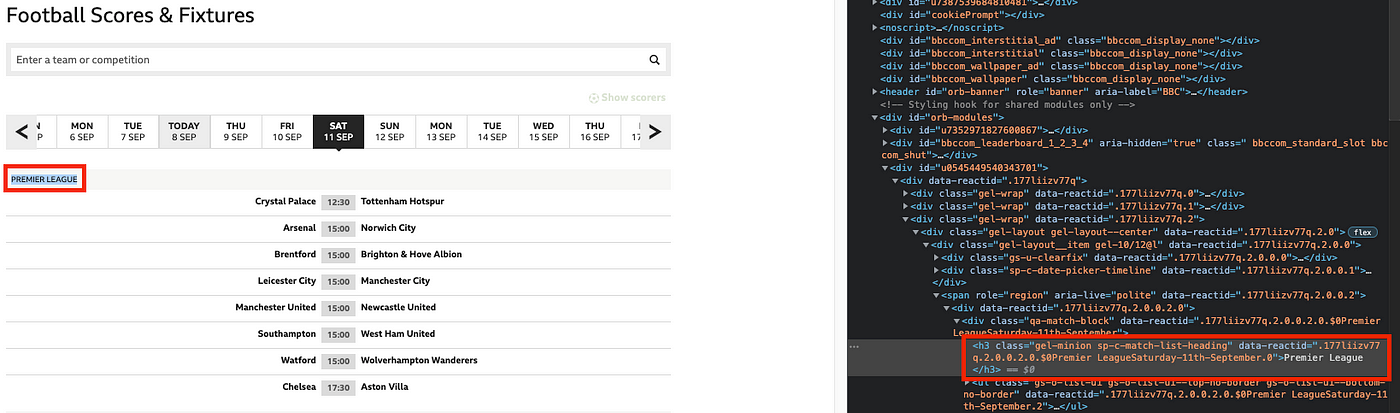
I can see that league names on this page have h3 (header) tags and class=“gel-minion sp-c-match-list-heading”. You’ll need to know both!
Repeat this step for all of the information that needs inspecting.
Step 4: soup.find_all()
This step is pretty simple: combine all of the tags and classes from above into two separate lists, and search for them within the soup variable using the find_all() function.
The 7 items that I inspected after “Premier League” all had the HTML span tag.
- The list “tags” contains all of the tags from the items that I inspected. In this case, I only had h3 and span.
- The list “classes” contains the 8 class strings from the HTML I inspected.
We are telling scraper to inspect the variable soup by looking at all h3 elements with the listed classes and all span elements with the listed classes.
We can call scraper:
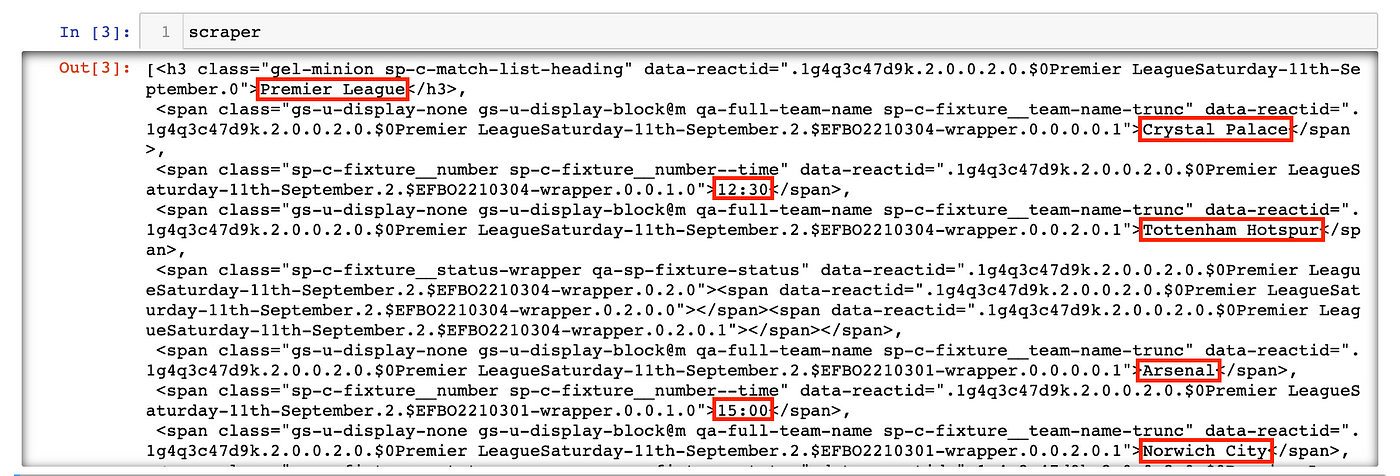
Let’s compare the first seven elements in scraper with the webpage:
There is still a lot of data cleaning, organizing, and formatting left to do, but at this point, we have successfully scraped the site for everything we need.
Step 5+: Python!
As I noted at the top, from here on is just Python. Rather than show all the code I used to build the rest of the program, I am linking my GitHub repository here. Feel free to check it out — and if you’re a football fan, download the program and use it on your own computer!
Final Product
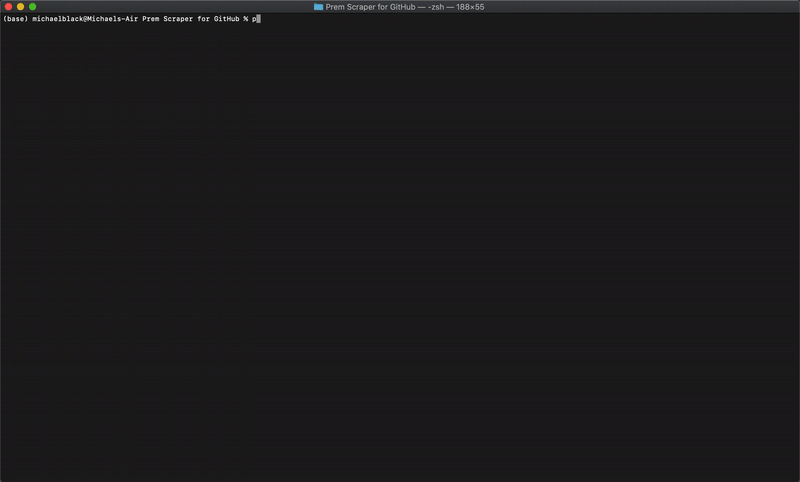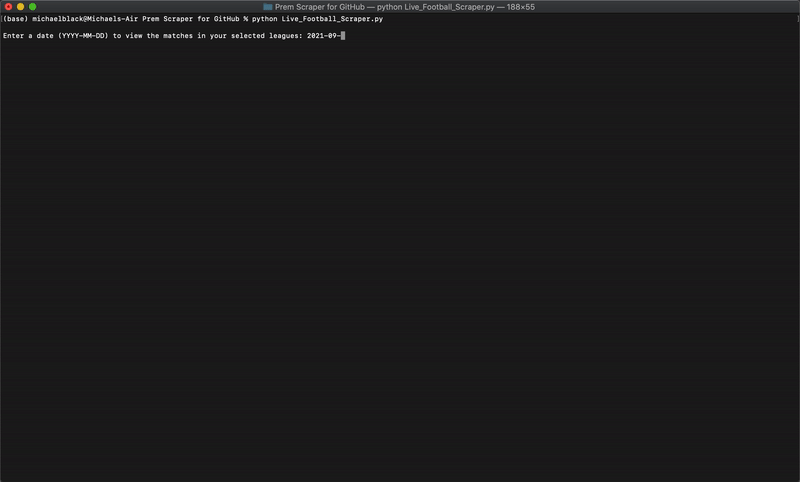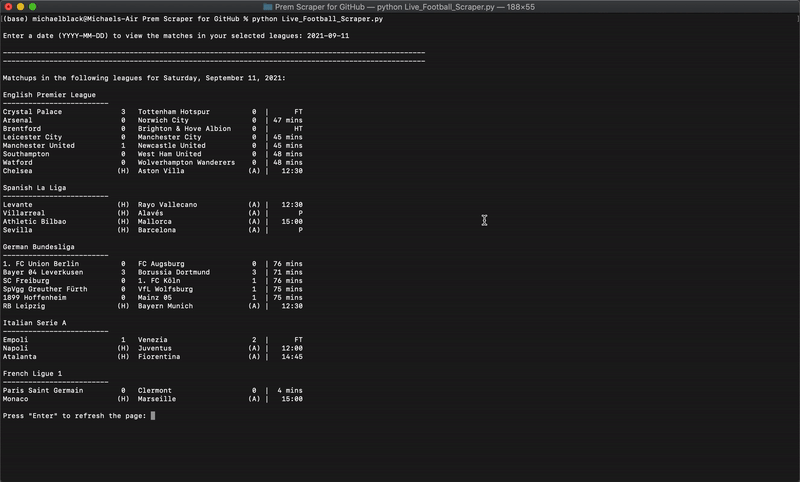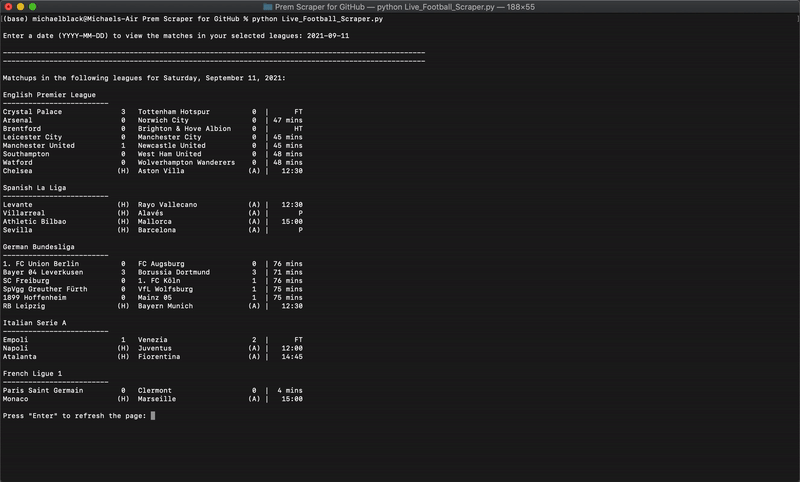
You now know the basics of static vs. dynamic websites, how to inspect a webpage, and Beautiful Soup! This brief introduction should be enough to have you comfortably using Python and Beautiful Soup to scrape the web for your own personal projects.
I hope you found this helpful.
Michael Black

Leave a Reply